










事例165
テキストマイニングによるアニソンの歌詞分析 -分析から時代背景を読み取ろう-
神奈川県立茅ケ崎西浜高校 鎌田高徳先生
高等学校情報Ⅰ・Ⅱ、テキストデータを可視化し、説明する活動が求められる

本日は、「テキストマイニングによる歌詞分析」の授業実践について発表します。
このテーマを扱ったのは、文部科学省高等学校情報科教員研修用教材として、「情報Ⅰ」の質的データの分析の学習でテキストデータの可視化が記載されていること。「情報Ⅱ」のテキストマイニングと画像認識の学習でMeCab(※1)注を利用したテキストマイニングがそれぞれ紹介されているからです。今後こうしたテキストデータをテキストマイニングにより可視化し、分析を加え、発表・説明する活動が求められると考えたからです。
※1 オープンソースの形態素解析エンジン
https://taku910.github.io/mecab/

質的データの分析は困難
授業で重要になるのは題材設定
データの分析は、これまで日本の研究のほとんどが量的データの分析だと言われています。質的データの分析は研究者の中でも実は難しいとされている分析手法です。

質的データの分析で代表的なものが「エスノグラフィー」という研究手法です。佐藤郁哉氏の『暴走族のエスノグラフィー』(※2)は、暴走族はなぜ暴走行為をするか、脚を拡げて座る行為の意味など、アンケート等の量的データによる分析ではわからない難しい事象について、フィールドワークを通じて観察・分析して明らかにします。また、箕浦康子氏の『フィールドワークの技法と実際』では、具体的なフィールドワークの研究手法について述べられています。
これらの手法を活用し、研究者が付きっ切りで教師の行動を観察しフィールドノーツを取ることで、量的データの分析からは見えない教師の授業での振る舞いなどを明らかにしています。つまり、量的に読み取れない事象を分析していくのが質的分析の醍醐味とも言えます。しかしながら、質的データの分析は困難を極めます。
※2『暴走族のエスノグラフィー―モードの叛乱と文化の呪縛』佐藤郁哉著(新曜社) https://www.amazon.co.jp/dp/478850197X
しかし、近年はソフトウェア技術の発達で、テキストデータを簡単に分析してくれるツールも登場しています。質的データの分析は容易になったものの、次の問題となるのは「何を題材として分析するか」ということです。
「情報Ⅰ・Ⅱ」で、テキストマイニングによる分析を行うとき、例えば太宰治の『走れメロス』などの本や、TwitterなどSNSの投稿、Webサイトなど様々なものが考えられます。

しかし、本はテキストの量が多く、SNSは言葉の揺らぎが多いため分析が難しく、Webサイトはどのサイトのどのデータを扱うか悩むことがあります。そこで私は、流行歌の歌詞の分析を考えました。
生徒が知っている身近な流行歌の歌詞は、データ量も多くありません。また、「思い出補正」の効果で、幼い頃聞いた歌を分析させると、生徒の学習に対するモチベーションも高まります。私は質的データの分析の入り口として、流行歌のテキストマイニングによる歌詞分析を断然お勧めします。
歌詞分析のねらいは、メディアリテラシーのベースとなる2つの力を身につけること
今回の発表の流れは、ご覧の通りです。
まず、歌詞分析のねらいについてです。この事例で大切なのは、テキストマニングの手法を学ぶこともありますが、それよりも歌詞分析を通して、メディアリテラシーを身につけることだと考えています。例えば、生徒に風刺画『It’s Media』やKevin Carter『ハゲワシと少女』写真を見せたとき、働くメディアリテラシーは次の2つです。

1つは「センスオブワンダー」でメディアを見て、ハッと何かに気づくこと。もう1つは気づいたことを、自分の言葉で説明する「ソシオロジカル・イマジネーション」です。メディアリテラシーの定義は様々ですが、グラフやポスター、写真などメディアに接して気づき、自分の言葉で説明する力が、ベースになると思います。授業実践では、こうした2つの力をテキストマイニングでアウトプットされたデータに対して働かせ、まず生徒にメディアリテラシーを働かせる学習活動に重点を置きました。

歌詞分析は身近なメディアで先行研究を活用でき、導入の題材として可能性
そのうえで、改めて歌詞分析を行なったのには3つの理由があります。1つ目は歌が生徒にとって身近なメディアであること、2つ目が見田宗介氏の流行歌の研究の内容が(※3)メディア分析として授業に活用しやすいこと、3つ目がテキストマイニング学習の導入として可能性があると感じたからです。

社会学者・見田宗介は『近代日本の心情歴史』(1978年)(※3)で戦前・戦後の流行歌を分析し、「マスメディア(大衆芸術)はその時代を生きた人たちの気持ちや心情を反映している」としています。そこで、時代背景が読み取れるかどうか、歌詞分析を通して考えてみようと、生徒たちが幼い頃に聞いた流行歌と、今聞いている流行歌の2つのグループを比較分析する授業実践に取り組んでみました。

まずは手作業による歌詞分析
大切なのは分析する前に仮説を立てさせること
ご紹介するのは、2年生の情報科の選択科目「情報と問題解決」の授業です。1コマ50分授業で、2コマ連続計8回分を使いました。内容としては、モーニング娘。とAKB48の歌詞を題材として、1・2時限は手作業による歌詞分析の体験。3・4時限はワードクラウドの説明をした上で、生徒に歌詞分析の仮説を立てさせ、5・6時限は個人作業でテキストマイニングによる分析を行ない、7・8時限で発表という流れで取り組みました。

手順に沿って説明すると、まず、歌詞分析から時代背景が本当に見えてくるか。それを体験してもらうおうと、生徒には手作業で、簡単な歌詞分析に取り組ませました。手順は
(A)歌詞から仮説を立てさせる
(B)歌詞のテキストデータから最小単位に文節で区切った歌詞カードを作る
(C)その後カードを使った整理法で模造紙にまとめ、考察を発表する
という形です。

(A)仮説を立てさせる
手作業による歌詞分析で扱う最初の曲は教員が選曲した、モーニング娘。とAKB48の代表的な3曲にしました。リリース年に約10年間のスパンがあり、10年前後の流行歌がその時代の人たちの気持ちを表しているか、クラス全員で歌詞分析に取り組みました。

ここで大切なのは、分析する前に、仮説を立てさせることです。モー娘。とAKB48の歌にどんな思いや時代背景があると思うか、例えば、1990年代は「女の子たちが元気だった時代」ではないかと仮説を立て、実際に分析させる。それと同時に、歌詞が著作権で守られている点も、しっかり説明した上で、歌詞分析に取り組んでいきます。

(B)文節で区切ったカードにする
今回は時間短縮のため、教員が事前に歌詞を最小単位の文節に区切った歌詞カードを作成していました。作成方法は、Excelに歌詞を入力し文節ごとにスペースを打ち込んだ後、Excelの区切り位置機能でスペースごとにデータを分割し、あとは罫線を付けて印刷・裁断すれば、文節ごとのカードが簡単にできます。

(C)カードを使った整理法を使ってまとめる
このカードを利用して生徒はカードを使った整理法でまとめていきます。この作業でのポイントになるのは、具体的なまとめ方を事前に生徒に説明しておくことです。いきなり膨大なテキストデータを手作業で分析するのは大変なため、「ポジティブとネガティブな因子を数えよう」、「品詞毎に分類しよう」など具体例を示しながら進めると生徒の活動はスムーズになります。

例えば、モーニング娘。「ザ☆ピ~ス!」はLet’sやPEACEなど同じ言葉、語尾には○○しようぜなど勢いをつける言葉が多用されていること。AKB48「Everyday、カチューシャ」は夏っぽい言葉が多用され、一人称の呼び方が違うことなど、生徒は流行歌の歌詞に埋め込まれた意味を発見し、話し合いながら分析していました。


ポジティブ/ネガティブ因子を数え、どんな時代背景があるか、生徒に発表してもらったものがこちらのスライドです。モーニング娘。は1990年代、単純で乱暴な言葉が多く、元気出そうぜと不景気をなくそうとする時代背景。一方、2000年代のAKB48の曲は、歌に目的がなく、女子が男子に語り掛ける歌詞といった形で、時代により若者たちが求めるものが違うのではないかということが、生徒たちの分析から見えてきました。

こうして手作業で歌詞分析をした後、大切なのは流行歌には作り手の意図が盛り込まれていることと、時代背景が反映されているのではないかと気づかせることです。
この事例を振り返ってみると、手作業による歌詞分析の作業時間は50分くらいが生徒も集中でき、適切であると感じています。それ以上の時間をかけても、あまり新しいことを発見することが難しくなると感じています。

テキストマイニングによる歌詞分析
手作業とはデータの見方が異なる点がポイント
手作業による歌詞分析の次は、テキストマイニングによる歌詞分析です。ここは手作業による分析と同様、(A)歌詞を選びこの曲とこの曲を分析したらこんな違いが出るのでは、と仮説を立てさせることが重要です。その後は(B)テキストマイニングをし、(C)出力された分析結果を考察するという手順です。

例えば、これはロボット好きな生徒が取り組んだ分析です。1990年前までと2000年以降のロボットアニメソングを分析しようと3曲を選び、「昔のアニソンはロボットの紹介が多いが、最近は歌にあまり意味がないのではないか」と仮説を立て分析に取り組みました。

生徒が仮説・分析する際は、ワードクラウドを使ってテキストマイニングに取り組みます。フォームの入力から歌詞を入力し、ワードクラウドに表示されたものから読み取れるもの、ポジティブ/ネガティブ因子を見て考えますが、ここで大切なのは、カードを使った整理とテキストマイニングの分析は、データの見方が違うと生徒に説明することです。
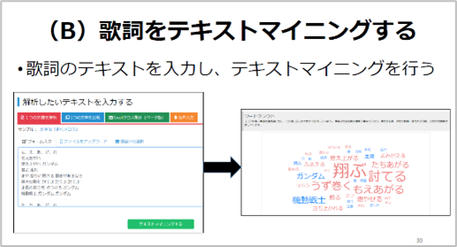
※クリックすると拡大します
実際に授業では、ユーザーローカル提供のテキストマイニングツールを使用していますが、このツールを使用していると生徒はあることに気づいて質問してきます。「先生、『走れメロス』の場合、王の出現頻度が18回、セリヌンティウスが15回なのに、なぜスコアはセリヌンティウスの方が上なんですか」と。生徒たちは、このテキストマイニングツールによる分析が、手作業による分析とは異なる分析手法であることに気づいていました。
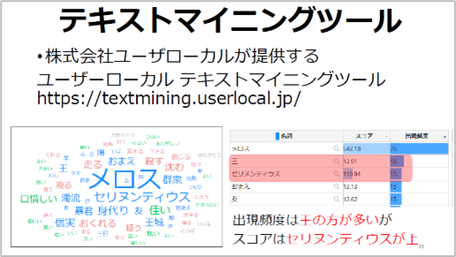
※クリックすると拡大します
このスコアのつけ方のtf-idf法について、埼玉県立川越南高校・春日井優先生の発表(※4)にまとめられています。このtd-idf法は文章の特徴を表す手法で、その単語に重みをかけてスコアを算出し、スコアの高い単語が特徴として出ていることを生徒に説明します。「王という単語は『走れメロス』以外の本にも出てくるが、セリヌンティウスはこの本にしか出てこない。だからスコアは高くなる。この歌詞分析でも同じですよ」と。このようにカードを使った整理方法とテキストマイニングで、分析方法やデータの出力が違うと気づかせたうえで、生徒に仮説を立てさせるのです。


また、テキストマイニングによる歌詞分析の利点は、とにかく分析に時間がかからないことです。100分間クラス34名全員で作業しても、カードを使った整理法では10曲が限界ですが、テキストマイニングでは100曲以上分析できます。分析数も、手作業では3~4人で1曲ですが、テキストマイニングでは1人で6曲ぐらい、報告も含めて100分程で分析ができます。
こうして「今と昔の流行歌をテキストマイニングで分析しよう!」と生徒たちに問いかけると、幼い頃に聞いたアニソンと、現在聞いているアニソンを分析対象とする生徒が34名中29名に上りました。自分の好きだった曲を扱うと、生徒の学習意欲を高める効果があり、授業中生徒たちはひたすら分析をし続けていました。改めて流行歌の歌詞分析はテキストマイニングの学習の題材に適していると感じました。

歌詞分析をどう評価するのかは難しいが
メディアリテラシー育成には効果的ではないか
では、生徒のアウトプットをどう評価したのかを説明します。
まず生徒には11枚程度のスライドを作成させました。1枚目は発表タイトルと名前を、2枚目は仮説を記入させます。「昔のアニソンは必殺技やロボットの名前が多いが、今の曲はあまり意味がないのでは」など仮説を立てさせることが重要です。

3枚目以降は、選んだ曲名と分析のねらい。どう今昔のグループで分析したのかを記入させます。それを踏まえ、一つずつワードクラウドの結果を、ポジティブ/ネガティブ因子に注目し、どんな違いがあるかを分析します。


※クリックすると拡大します

※クリックすると拡大します
こうして分析した結果からわかったことを一言で結論にまとめます。この生徒の発表では、かつてのアニソンは想像の世界を歌っていたが、今は登場人物とか主人公が歌う曲が多く、ロボットから人に時代背景が変わってきたと結論付けていました。

このように11枚程度のスライドを評価しましたが、質的なアウトプットを評価するのは難しく、テキストマイニングで出てきたものをどう分析すればよい評価か、一概にはなかなか言えませんでした。そのため、スライドの記入と分析結果が自分なりに述べられていれば評価するとして、以下の基準により10点満点で評価しました。生徒たちはテキストマイニングにより出てきたデータから発見したことを説明しなければならないという点で、メディアリテラシーの育成には、効果的だったと思います。

生徒たちの分析をまとめたものが下図です。
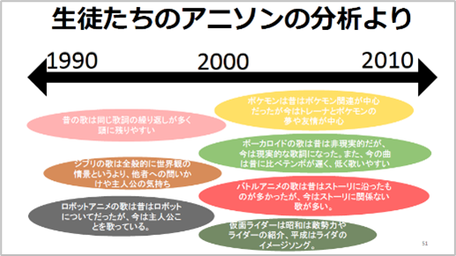
生徒たちの発表をまとめると、流行歌には時代背景が反映されていると言いましたが、100曲近く分析した結果、昔のアニメソングは想像の世界を歌っているが、今のアニメソングは現実の世界や人を歌っていること。昔の歌は主人公の周りのものを重点的に歌っていたが、今は主人公そのものや主人公を通して見る世界を歌っているアニメソングも多いのではないかという結果になりました。

今回の実践は始めたばかりの実践ですので、これから分析数や分析方法を検討していくことでテキストデータの分析する実践として完成度を高めていきたいと思います。
また、発表後に様々な情報科の先生方と今回の歌詞分析の事例について議論する機会を設けることができ、以下のような2つのアイデアをいただきました。ご参考になればと思い、この場を借りて紹介させていただきます。(1)手作業による歌詞分析とテキストマイニングの歌詞分析を比較し、人ができることとAIができることに気づかせる授業に繋げる。(2)生徒1人あたり今と昔の流行歌2曲の分析を行わせ、40対40の大きなデータ群で比較分析をする。まだまだ始めたばかりの事例です、皆さんと一緒に質的データの事例を作っていければと思っています。
[質疑応答]
Q1:
解釈はどのようにさせていますか。解釈の根拠については、どのように説明させていますか。
A1鎌田先生:
最初に述べたように、質的データの解釈は難しいです。基本的なスコアや言葉の関係性以外の根拠は現段階では、まだ見えていません。まだ歌詞分析には見えないデータが埋め込まれていると思います。今回の実践では、これら埋め込まれたデータについて考える時間は確保できなかったと思います。今後は生徒たちに、どのような根拠で解釈したのか発表させる形も考えていきたいと思います。
Q2:
テキストマイニングでは、品詞の係り受け(例えば名詞→動詞など)も見たりしますが、そのあたりはどのように扱っていますか。
A2鎌田先生:
私のところでは、そこまではまだ扱えていません。手作業による歌詞分析では、単語をグルーピングして矢印で係っている部分まで扱いましたが、今回は100分間の授業で1人6曲扱う授業内容だったので、そこまで踏み込んだ分析の実践ではできていません。ただ、私たちもデータ分析やテキストマイニングに取り組む中で、どこまで踏み込んで取り組むべきか、私自身もすべてが見えている状態ではありません。とはいえ、テキストマイニングには流行歌など歌詞分析では、品詞の係り受け分析を入れるべきかまだわかりません。来年度以降、実際に取り組んでみて効果的かどうか、検証していきたいと思います。
第13回全国高等学校情報教育研究会全国大会(オンライン大会) 講演より