










事例100
問題解決に自然言語処理と機械学習を用いた協働学習の実践
埼玉県立川越南高校 春日井優先生

今回は、問題解決に自然言語処理と機械学習を用いた協働学習の実践についてお話しします。
次期学習指導要領の内容にびっくり!?

まずは本題の発表の前置きということで、少しお話をさせていただきます。
7月17日に次期学習指導要領の解説書が出ましたね。私の第一印象ですが、とにかくびっくりした、どうしよう?!という感じです。特に情報II。キーワードだけ拾ってみても、まず「仮想現実・拡張現実・複合現実のコンテンツ」。データサイエンスでは、「回帰・分類・クラスタリング」とか「重回帰分析」。あと、システムの方では「プロジェクト・マネジメント」とか「プログラムを統合」するとか。最後の(5)、課題研究にあたるところでは、「問題の発見・解決の探求」。この1年間、いろいろ想像はしてきましたが、「え? ここまでやる?」というのが正直な感想でした。
「情報Iでプログラミング教えるだけでも大変だから、情報IIなんてやれないよね」などという声もちらほら聞きますが、今回私が言いたいのは「情報II、やりましょう!」ということです。
まずは、情報IIとは何かということをいろいろ調べてみました。こちらは情報IIの目標ですが、情報Iとほとんど同じです。違うところだけ赤字にしました。「創造的」と「その発展に寄与」という言葉が増えただけで、それ以外は一字一句違っていません。




目標についても、(1)は実際の内容ですので情報I(青字部分)とはかなり違いますが、それ以降を見ると、「創造的」という言葉が、次の(3)では「新たな価値の創造を目指し」情報法社会に主体的に参画し、「その発展に寄与」する態度を養う、という言葉が加わっています。
情報Iは比較的近い将来について、情報IIは高校生が担うべき将来の社会について学ぶ

こうしてみると、情報Iと情報IIの一番大きな違いは、情報IIは、より「新たな価値の創造と発展に寄与する」ということではないかと思います。
これを私なりに整理した結果、情報Iは比較的近い将来のことを学び、情報IIはもっと将来、高校生たちが社会を担っていく時の姿を創っていく科目ではないかと考えました。
次の学習指導要領が始まる2022年に高校生に入学してくる人たちが38歳になる2045年には、シンギュラリティがやってくると言われます。その時彼らは社会の中堅、まさに働き盛りになっています。そのときにどういう時代になっていくかというのを、今から考えなければいけないのではないか、と思っています。

先ほど申し上げたシンギュラリティについて言えば、「人工知能」で検索した無料イラストサイトで見つけた画像がこちらです。人工知能と仲良くしていくのか、あるいは下僕になってしまうのか、このどちらの時代を作るのでしょうか。この右側の絵ですが、左端が切れています。実はこの左側に、人工知能を作っている人や、学習データを与えている人もいます。シンギュラリティが来るというだけでなく、それを操る人もいることも考えなければいけないと思っています。
情報IIをやるかやらないかというのは、何となく我々教員が、授業ができるのかできないのかという物差しで測られているような気がしてしまいます。しかしそうではなくて、今の高校生が社会の中心となる2050年がどのような社会になっていくか、そのために何ができるかという物差しで測るべきであって、その上で授業をやるのか・やらないのかということを考えなければならないと思います。
情報IIの柱となる「データサイエンス」を先取りして、「機械学習」の基礎をやってみる

そこで、少し先取りではありますが、今の時点で情報IIの「データサイエンス」に近いことを何かできないかということを考えて実践を進めてきました。今回は「モデル化とシミュレーション」の単元で、Bag of Wordsというモデルを使って機械学習(単純ベイズ分類器)をやってみた授業をご紹介します。

なぜ機械学習を授業で行ったのかにつきまして。先ほどお話ししたように、昨年情報I・情報IIの大まかな内容が示されたとき、情報IIで「情報とデータサイエンス」を行うということは出ていました。さらに、一昨年の全国大会の講評講演で、鹿野先生が「ベイズの法則」というお話をされていたので、「そこが来るか」というのを聞き逃さず、何に使えるかなということを考えていたところでした。
この「データサイエンス」というのは、人工知能につながる機械学習のようなことも扱っている分野です。データから計算結果を出すことで、コンピュータや人工知能がどんな仕組みで動いているのか、という内側を知ることができます。コンピュータがどのような手順で結果を出すことを知ることで、結果をどのように捉えていったらよいのか。さらに人工知能の精度がより高くなったときに、どう使いこなしていくのかを考えていく必要があるだろうと考えて、この授業を行いました。

単純ベイズ(ナイーブベイズ)分類器を選んだ理由は、まず、文章がデータなので、対象を多量に集めやすいということ。日本語の文章をコピペで集めて処理を使えば、後で使いやすいということがあります。
次に、コンピュータに文章を答えさせることができて、いかにも人工知能っぽいというのがあります。実際に迷惑メールフィルターでも使われているらしいです。また、仕組みが高校数学程度の知識で十分理解できるということがあります。「数学はイヤ」「確率なんか大嫌い」という生徒がいても、最後は長方形の面積計算で解決できるということがわかれば、何とかなります。

授業の流れとしては、まずコンピュータが動作する仕組みと情報の表現の仕組みを抑えます。この辺りは、あまり深く説明しません。その後に機械学習の知識と技能の習得、最後にグループでの問題解決という流れで行いました。

実際の授業の内容です。まず、「機械学習以前」について。先ほどの3段階の一番下にあたる部分です。文字のディジタル化と文字コードの話は、ここでは割愛します。次に、コンピュータが動作する仕組みということで、Pythonによるプログラミングをやりました。ここにはあまり時間をかけず、かつある程度のことは理解しておいてほしいので、プログラミング学習サイトのProgate(※1)を使って個人で勉強しておくようにさせました。このPythonのIとIIをやれば、変数、条件分岐、リスト、辞書、繰り返しくらいまではできるようになります。今回の機械学習のプログラムは、この程度ができれば十分書けるものです。
形態素解析、tf-idf、Word Cloudをやってみた

授業では、形態素解析、tf-idf(Term Frequency - Inverse Document Frequency)、Word Cloud(タグクラウド)という三つの自然言語処理を行っています。Word Cloudを入れたのは、今回、「情報I」の学習指導要領にも「タグクラウド」という言葉が出てきていたからです。

まず形態素解析です。日本語の文章は、単語同士つながっていて分かち書きされていないため、コンピュータは理解できません。そのため、意味を持つ最小単位の「形態素」に分けて品詞を判別する作業(=形態素解析)が必要です。ここは「Janome」というツールをライブラリに入れて使いました。ただし、Janomeは固有名詞には弱いので、「ディズニーランド」が「ディズニー」と「ランド」分けられてしまう、ということはある、というのも経験します。

tf-idfは一見難しそうですが、実は数えて頻度を出すだけです。ですから、「重要な言葉は何回も出てきます」ということで、何回も何回も繰り返されれば、それだけ頻度も高くなるよね、ということです。

確認するために、この裏でどのような数字が動いてるかを手で数えました。まずtfは全形態素数分の形態素の出現回数です。「例」に出てくる5つの単語の中には、「果物」が1回だから1/5、「ケーキ」は2回だから2/5です。
こちらはidfの考え方です。ここに出ている単語を見て、どんなスポーツなのかはすぐわかりますね。オフサイド、スリーポイントシュート、ホームラン、トライといえば、それぞれサッカー、バスケットボール、野球、ラグビーとわかりますが、最後の「ボール」だけよくわかりません。上の四つは特徴がありますが、ただの「ボール」はそのような特徴がないですよね。idfは、このように1単語で特徴を表すものを抽出するというイメージで捉えると分かりやすいかなと思います。

idfの出し方です。こちらの語群を見ると、「果物」はりんごといちごに出てきます。「ケーキ」はいちごだけにでてきます。ということで、この場合は文が3つありますから、逆数にして「果物」は3/2、ケーキは3/1としたものにlogがついています。「logがくっつく」というと意味がよくわかりませんが、「100%に近いほど価値がなく、0%に近いとかなり価値が高い」というイメージがわかりやすいと思います。

次に、特徴語の可視化を行います。
Pythonでtf-idfを計算して、Excelに出力します。そして、Excel上で「する」や「ある」というような特徴語にはならない単語などのノイズを除いてキーワードを探してグラフ化します。
また、図の下の方はWord Cloudを使ったものです。これもライブラリに入れて使いました。ライブラリに入れるのが難しいですが、webにもありますので試してみていただけるとよいと思います。このグラフを作ること自体は難しくありません。

先ほど情報Iに「タグクラウドが出てくる」というお話をしたのがこちらです。「(4)情報通信ネットワークとデータの活用」でテキストマイニングとか、タグクラウドとか、単語の出現頻度といった活動が書かれていますが、今お話しした活動はこの辺りに関係するのかなと思っています。
単純ベイズ分類器を条件付確率と絡めて説明
次に機械学習の手法の一つ、「単純ベイズ分類器」と、そのもととなる「ベイズの定理」を取り上げました。「ベイズの定理」を、数学Aで学習している条件付き確率と関連付けて説明します。

例えば、全てのメールのうち普通のメールが0.8、迷惑メールが0.2の割合であります。その中で、「お金を振り込んでください」という言葉が入っている確率は、普通のメールでは0.05であるのに対して、迷惑メールでは0.8です。ですから、「お金を振り込んでください」という言葉が入っているメールが迷惑メールである場合は、この赤い斜線が入っている部分に限られるので、この部分の面積を求めればいいですよ、という程度の話です。

確率は数学でやればいい、という話がありますが、事前の予測があって、そこに何らかの情報を得ることによって、その予測が変わるということであれば、これは完全に情報科の守備範囲ではないかと思います。それを数式としてやったのが、単純ベイズ分類器ということになります。
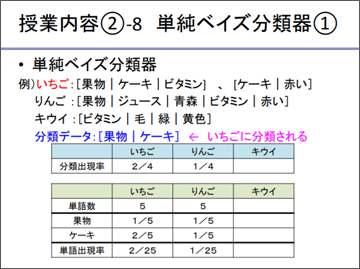
単純ベイズ分類器については、ベイズの定理の計算結果によって分類できることを、果物の分類を題材に説明しました。いちご、りんご、キウイの3つの果物の特徴を説明する単語がそれぞれ提示されています。ここで、分類させるために「果物」「ケーキ」という単語が出てきたとすると、いちごの特徴にあたる単語のうち一致する確率は2/4ですが、りんごは1/4だから、これはいちごに分類される、ということになります。

ところが、ここに挙げられた特徴語を見ると、キウイの中に「果物」という単語が入っていないので、キウイのところで果物が出てくる確率は0ですから、「キウイは果物ではない」ということになるという問題が発生します。こういったことを避けるために、もとの語群のリストを見て、足りないところには少しずつデータを加えておくんだよ(※2)、という話をしました。
(※2)学習データに含まれなかった単語を分類する(ゼロ頻度問題が生じた)場合に、確率がゼロにならないように緩和するスムージングという方法

また、コンピュータの仕組みを知ってもらうために、わざと無茶な計算をやらせてみます。例えばPythonで「0.1の300乗」を計算させると、コンピュータがアンダーフロー(※3)を起こして、表示は0になります。このようにアンダーフローを起こした時は、対数(log)を使うと程よい値で計算できるよ、ということも伝えて、データの扱い方や精度、計算の手順などに目を向けさせることも行っています。
(※3)浮動小数点演算処理について、計算結果の指数部が小さくなり過ぎ、使用している記述方式では数値が表現できなくなること

ここまでの内容は一斉授業で行いました。これを行うにあたって、この次に活用・研究につなぐために配慮したのが、図に挙げた五つの点です。
tf-idfと単純ベイズ分類器で「役に立つもの」を作ってみる
実際の授業内容の二つ目、グループでの問題解決です。「tf-idfと単純ベイズ分類器を、社会における問題発見や解決への 適用する仕方を考えて提案しなさい」というもので、問題発見をするところから全て生徒に考えさせます。
ただ、初めてやるのでさすがに例示がないとたいへんなので、小江戸と呼ばれる3つの観光地を例にして、差別化をはかるための特徴語を抽出して単純ベイズ分類器にかけ、観光案内を作る、というものを見せました。その後、何を題材にしてどんな仕組みを作るかについては自分たちで考えさせました。


問題の発見に関しては、個人で内容を考える→グループ内で意見交換して視点を整理する→テーマを発表して他のグループとの間で意見を交換する、というステップを踏みました。

作業の手順は図のとおりです。
テーマに沿ってキーワードとなる語句や事項をwebサイト上で探し、データとして必要な部分を抽出してコピペします。これを、与えられたプログラムで処理して、特徴を見ながら特徴を見つけ、問題点や提案などを発表資料にまとめるというものです。
生徒が作ってきたテーマと、成果物が下図です。



自分たちが作った仕組みがうまく動かないことから、機械学習の落とし穴が見えてくる

生徒の気づきについてご紹介しましょう。例えば、「観光地の特徴・旅先案内システム」を作ったグループでは、沖縄担当の生徒が頑張ってデータをたくさん集めた一方で、札幌の担当の生徒のデータが少なかったために、検索すると沖縄ばかり出てきてしまう、という問題が起きました。
実は、ベイズの定理にはかなりフレキシブルなところがあって、「理由不十分の原則」つまり、事前確率の確率を変える理由がなければ等確率にしましょう、というものがあるので、これはデータが多いか少ないかによる差が出ないようにするため、データの行数で調整できるようにしました。

商品の特徴を入力して購入商品を提案するシステムを作った生徒からは、「『使いやすいペン』と『使いやすくないペン』を調べると同じ結果が出てしまうのはどうしてか」という質問が出ました。これは、マッチングさせると、現れる形態素がほとんど同じだからです。これは、某グルメサイトで「このあたりでいちばんおいしいイタリアンレストラン」と「このあたりでいちばんおいしくないイタリアンレストラン」で同じ店が出てくるという、有名な話と同じです。
さらに、「朝のおススメ番組を提案する」というシステムを試したら、「(TBSの)『あさチャン!』と入れると、(日本テレビの)『ZIP!』って他の番組の名前が出てきてしまう」ということを発見した生徒がいました。この生徒は、「あさチャン!」の語群データの中に「あさチャン!」という言葉自体が入っていなかった、ということに自分で気づいて納得していました。

こういった活動を通して、生徒は検索システムではデータの量が大事であること、そのデータを、どういうところから偏りなく取ってくるかが大事であること、そして取ってきたデータに偏りがあると、身近なものを検索しても寡占状態を引き起こす可能性があることに気がつきました。
また、どんなデータを与えるかによって、出てくる結果が変わってくるというところに注目した生徒もいました。このように、検索システムの仕組みを知っていることで、コンピュータの使い方について、さらに見えてくるものがあるのではないかと思います。今「社会と情報」をやっている学校でも、つながる話ができるのではないかと思っています。

最後に、今回の実践のまとめです。アルゴリズムが決まっているものを、プログラミングとして授業で扱うのは難しかったです。機械学習に重点を置くのであれば、Weka(※4)などのツールを使った方がよかったかもしれません。また、人工知能や機械学習に関する法整備のあり方についても考えていかなくてはいけないと思っています。
最後に、ビッグデータとプライバシーなどの人間生活との関係ということにどのように言及していくか、というのも今後の社会的な課題になっていくのではないかと思っております。このような内容は、「社会と情報」にもつなげられると思います。こういったことを考えるためにも、ぜひ情報IIを開講していきましょう。
(※4 )ニュージーランドのワイカト大学で開発した機械学習ソフトウェアで、Javaで書かれている。GNU General Public License でライセンスされているフリーソフトウェア。[Wikipediaより]
第11回全国高校情報教育研究会全国大会事例発表より