










事例90
機械学習の仕組みの指導と機械学習を用いた問題解決の授業実践
埼玉県立川越南高校 春日井優先生
人工知能とうまく付き合うために機械学習の仕組みを知る

今回は、「機械学習」の仕組みの理解と機械学習を用いた問題解決の授業実践例についてお話しします。
機械学習をテーマとしたのは、人工知能の発展によってこれから10~20年の間に半数近くの仕事がなくなると言われる現在、人工知能のもととなる機械学習について学んでおく必要があると考えたからです。
人工知能は我々人間を超えた存在と感じてしまいがちです。しかし、その仕組みについて理解をして人間が使いこなすことや、仕組みから見えてくる限界を知る経験をさせたいと考えました。そのような経験を通して、興味を持ったり、効果的に活用しようとしたり、人工知能が出す答えを批判的に捉えたりすることにつながると考えました。既に公表されている次期学習指導要領の中学校総則編でも人工知能について触れられていますし、高校共通教科「情報Ⅱ」の「データサイエンス」を意識した内容にもなっています。

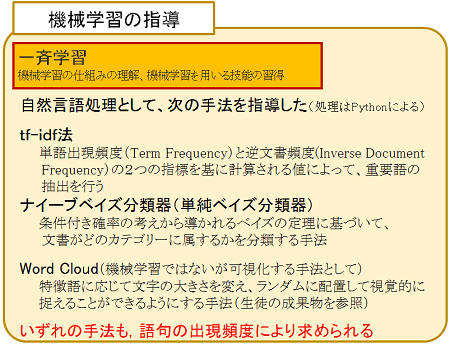
機械学習には、下図のように様々な種類がありますが、今回扱ったのは、事前に与えられたデータを「例題(=先生からの助言)」とみなして、それをガイドに学習(=データへの何らかのフィッティング)を行う「教師あり学習(Supervised learning)」です。生徒達がよく使うOK GoogleやSiriなどの検索エンジンがどのような仕組みになっているかを知り、人工知能とどのように付き合っていけばよいかを考えるために行いました。本校は3年生で「情報の科学」を実施しており、「モデル化とシミュレーション」の単元で、説明は6時間、グループでの活動は6~7時間かけて行いました。

具体的な活動として、グループごとにテーマを決めて、条件にあたる文章を入れるとそれに合ったものを選び出してくる検索エンジンのような働きをする部分を作りました。
言語は人工知能のプログラムにもよく使われるPythonを使いました。この授業を受けた生徒は、Pythonについては夏休み前までにProgate(※)でLesson1、Lesson2までは自分達で終了しています。自分達で全て書くのは難しいですが、プログラムを読むことはできるので、120行ほどのサンプルコードを渡して適宜変更させました。
最初に自然言語処理の手順を学びました。まず単語を形態素(言語で意味を持つ最小単位)に分解する作業を行います。まずChaSenやMecabなどの日本語の形態素解析(※)エンジンを使って、文章を形態素に分解する作業をやってみます。次に、Pythonに形態素解析のブログラム(janome)を組み込み、同じように分解できることを確認します。

※形態素解析(morphological analysis):文法的な情報の注記のない自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素の列に分割し、それぞれの形態素の品詞等を判別する作業。 [Wikipediaより]
代表的な2つの方法を同時に学ぶことで、どんな言葉が選ばれるのかという感触をつかむ
次に、tf-idf法とナイーブベイズ分類器(単純ベイズ分類器)の二つの方法の原理を説明して仕組みを理解させた上で、それらを実際に行うそれぞれの方法でプログラムを確認しました。二つの方法を両方行ったのは、二つとも「特徴語」(※)の出現度合いが多いものを選んでくるというところは共通しているので、両方を見ることで、コンピュータがナイーブベイズ分類器で学習したデータからコンピュータが何を選んでくるかということを、生徒が予想しやすくなるからです。
※「球技」の中で、例えば「オフサイド」であればサッカー、「3ポイントシュート」ならバスケットボール、「サービスエース」ならテニスか卓球というように、特徴を決定づけるもの
ナイーブベイズ分類器の説明の前に、ベイズの定理の数学的な意味については、迷惑メールの例を使って説明しました。文系の生徒には、条件付き確率を学習してから時間がたっていたため、かなりきびしいところもあったようです。
その後、自分達が選んだテーマに沿って、選ばれる対象となる語をメンバーで分担してインターネット上で検索し、説明として出てきた文章をコピペしてメモ帳に貼りつけてストックしていくという作業を行いました。
例えば、「おススメの温泉」を検索するチームであれば、鬼怒川、熱海、草津、別府、箱根…といろいろな温泉の公式ページやWikipedia、温泉に行った人のブログなどをできる限り検索して、特徴のありそうな文章をコピペしていきます。これはひたすら手作業です。この作業を自動化することも考えましたが、そうすると生徒は結果しか見ないでしょう。手作業で探している間に、自分なりに特徴に気づき、それが機械学習にどのように反映されるかということをある程度予測できるようになります。
プログラムにテキストを入れる時は、そのまま入れるのでなく、ケースによって多少編集の必要があります。また、余計な言葉に引きずられることを避けるため、グループによってはプログラムを修正することにより名詞だけなど品詞を限定したところもありました。
思い通りの結果が出ないことから見えてくる機械学習の盲点

データのストックができたら、tf-idf法とナイーブベイズ分類器の両方のプログラムに同じデータセットを入れ、実際に条件を入れて動かしてみます。
特徴語の抽出結果は、エクセルのグラフとワードクラウドの両方で出力します。その結果により、ナイーブベイズ分類器で計算する際に、どの語句が計算に影響を与えているかを見ることができます。ナイーブベイズ分類器の結果は、単に何に分類されたかという結果だけではなく、その分類になる確率も数値として結果を出力します。OK Googleなどでは、例えば「賢くて活発でかわいい犬が欲しい」というと「ポメラニアン」が一つだけ出てきますが、その裏で計算が動いていて、どの程度の確率でこの結果が出てくるのかということも実感することになります。

この活動で面白いのは、思った通りの結果が出てこない、ということが発生することです。例えば、先ほどのおすすめの犬を検索する仕組みを作ったグループでは、「賢くて活発でかわいい犬」ではポメラニアンでしたが、「強い犬」と入れてもやはりポメラニアンが出てきました。ポメラニアンは強い犬ではないだろうということになるのですが、これはもともとのデータセットの質の問題です。
これはグループで分担した時に、例えばポメラニアンを担当した生徒が非常にまじめで、1時間に1000行以上のテキストを拾ってきたのに対して、シェパードを担当した生徒はそこまで一生懸命やらなかったのでテキストが集まらなかったとすると、拾ってきたテキストの行数を事前確率として用いて計算させているため、結果的にシェパードの条件を入れてもポメラニアンが出てきてしまうこともありうるのです。また、「賢くなくて活発でなくかわいくない犬」と入れてもポメラニアンが出てくることに気が付いた生徒もいます。単純に語句の一致に基づいて計算している仕組みによるものです。
これらの活動を通して、生徒は検索エンジンで出てくる答えは、確率的な考え方に基づいて出現回数の数値から算出された値から出てきていること、またプログラムに与えられたデータの質によって結果が変わってしまうことがわかります。そして、検索結果を鵜呑みにするのでなく、批判的に捉えることが必要だということも実感できるのです。
また、この活動では自分達が作ったシステムを説明するユースケース図を作りました。どのような予想や分析ができるのか、その予想や分析をどのような人が利用すると有効に活用できるのかを整理してシステムの役割を明確にします。ふだん使われている様々なシステムを構築するにあたってこのような手順が踏まれていることも経験しました。

この授業で使ったプログラムやワークシートは、下記のURLからダウンロードしてお使いいただけます。ぜひお試しになってみてください。
http://www.kawanan-info.sumomo.ne.jp/kanagawa/