










データ科学の研究者・教育者視点で読み解く新情報科の「データサイエンス」
早稲⽥⼤学創造理⼯学部経営システム⼯学科 蓮池隆先生

私の専門は、オペレーションズ・リサーチ(OR)という分野です。ORは、いわゆる最適化や数理モデルなどいろいろな数学的アプローチ、統計的アプローチを用いて、実社会の問題に対する意思決定の支援を行う研究分野です。ORは、ダイレクトなデータサイエンスではありませんが、意思決定として非常に役立つ分野です。
早稲田大学では、経営システム工学科に所属しているので、やはり経営やマーケティングの内容のデータ解析を行いたいという学生が多いです。そういった意味でのデータ解析系の研究も広く行うようになって、現在に至ります。
大学の教員ということもあり、新課程の教科「情報」についてある程度は勉強していますが、まだ高校現場での「情報」に関する指導に関しては勉強不足の点があることはご容赦いただければと思います。
また、データサイエンス自体は、後でも述べますが、広い分野の多角的な視点が必要な学問です。私の専門は、データサイエンスの中でもいわゆる機械学習やディープラーニングといった先端的な理論の分野ではありませんので、今日のお話は、データサイエンスに関わる研究者の一個人の意見として捉えていただきたいと思います。

今回は、まず「データサイエンティスト」という意味で、社会でどれだけ・どのような人たちが求められているのかということと、高校教科『情報』とのつながりについてお話ししていきます。
次に、実際のデータ処理・データ分析に関して、教科「情報」とのつながりについてお話しし、そして、実際にデータサイエンスを行っていく上で重要になる、データそのものの質に関するお話をします。
ここまではやや固いお話ですが、次は結局データサイエンティストというのは、データがないとどうしようもないということで、中盤では実際にデータを扱っていくといろいろなことが起きるよ、見えてくるよ、というお話をして、最後にまとめとしたいと思います。

時代は今、「データを扱える人」を求める
まず、今の世の中はどうなっているのか。皆さんもご存じかと思いますが、今やデータを持っていない企業は、なかなか競争に勝てなくなってきているという状況にあります。
ここに書いてあるとおり、いわゆるGAFAと言われる巨大IT系企業がデータを牛耳っていますが、もちろん、これらの企業が持ち得ないような、それぞれの企業独自のデータもたくさんあります。
実際、多くの企業はそういったデータを持っていますが、どう使えばよいのか、というところに悩んでいるところが多いというのが現状です。
そのデータも、電子媒体でなく昔ながらの紙媒体なので、まず電子媒体へ落としてコンピュータで解析できるような状態にするにはどうすればよいのか、あるいは電子媒体のデータはあるけれど、それをどう使えばよいのか、わからないところも多いです。
今回、高校で『情報Ⅰ』が、来年からは『情報Ⅱ』が始まるということで、3年後にはこれを学んだ卒業生が大学へ入学します。そして、少なくとも10年後には、データサイエンスを学んだ高校生・大学生が社会にどんどん出て行くという状況になります。そうすると、データを扱える人材のニーズは非常に高まってくることになります。

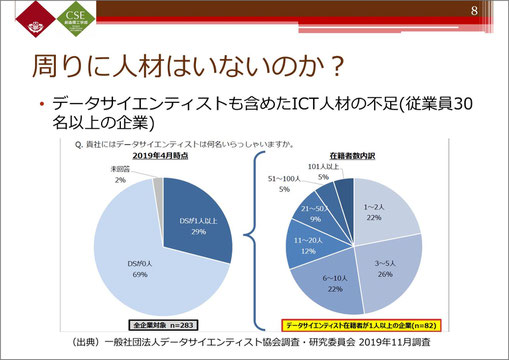
データサイエンティスト協会の調査では、従業員30名以上の中・大企業で、ICT人材、要するにデータサイエンスを扱えるデータサイエンティストがどのくらいいるか、というアンケートを採ったところ、「1人以上在籍する」という企業は3割程度しかありませんでした。その3割の内訳も、半数が5人以下となっています。
従業員30名に対して5人であれば、相当多いことになりますが、企業側としては、データサイエンティストが従業員の7割はいてほしいとしています。つまり、現状ではデータを扱える人材が社内にいないため、データをどう扱えばいいのかがわからないという企業が7割近くあると見ても、過言ではないかと思います。
※クリックすると拡大します。
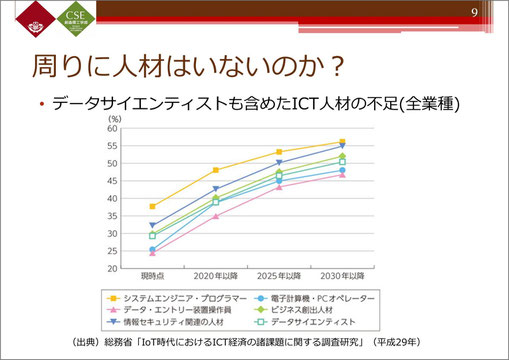
こちらは総務省の、データサイエンティストも含めたICT人材の不足に関するデータです。
平成29年時点でのデータで、やや古いものですが、今後2030年に向けて、ICT人材がどんどん不足していくと見られており、データを扱える人材を増やしていかなければいけないという社会的な要請がうかがわれます。
※クリックすると拡大します。
データサイエンティストとはどんな人か
データサイエンティストというのは、基本的にはデータを扱える人たちのことを言いますが、いろいろな定義があります。
辞書等々にも様々な形で書かれていますが、要約すると、実際にデータが処理できて、分析ができて、最後にここが重要なところですが、解決方法を提示・評価できるという人材のことです。そして、こういった人が今後必要になってくるということです。
つまり、プログラミングができて、統計やデータマイニングの手法が使えて、さらにそれをきちんと他の人に説明できるデータサイエンティストが必要になってきています。個人的に見ても、かなり幅広い、総合的に高度な能力がされています。

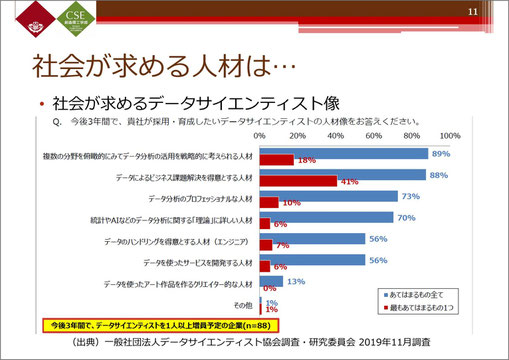
先ほどお話ししたデータサイエンティスト協会の調査で、2019年の段階で、今後3年間(つまり今年まで)に採用・育成したい人材に関する質問がありました。
最も当てはまるものとしては、やはり「ビジネス的課題を解決するために、その企業にとって必要とされているもの、実際の利益につながるような人材」ということですが、複数回答を可とすると、一番上位に来るのが、「複数の分野を俯瞰的に見て、データ分析の活用を戦略的に考えられる人材」、つまり、いろいろな分野を総合的に見て分析できる人が求められているということになります。
データ分析のプロもほしいし、統計やAIなどデータ分析の「理論」に詳しい人もほしい。データのハンドリングができる人、データを使ったサービスの開発ができる人など、基本的にはデータの扱いにつながる素養のある人は皆ほしい。
もちろん、その企業の利益につながることが必要ですが、データサイエンティストという観点では、分析できて、理論に詳しくて、ちゃんと解決できて…、ということを全て合わせ持った人材が求められている、というのが現状です。そういった人材の育成のために、「情報Ⅰ」に「データの分析」がダイレクトに入ってきたのかなと思っています。
※クリックすると拡大します。
学習指導要領には、情報の科学的な理解に裏打ちされた情報活用能力を育成し、問題発見・解決に活用するための科学的な考え方ができる人を育てましょう」ということが書かれています。
そして、情報の活用を闇雲に実施することはNGですよ、とも書かれています。要するに、目的を持って、的確な手法でデータを収集・分析できて、それを活用する能力が求められているということになります。
では、その目的とは何か。的確な情報の収集・分析とは何か。この辺りこそ、今後考えていかなければいけないところになってくるのかなと思います。

データ処理・分析と教科「情報」
ここからは、データ処理・分析という視点からお話を進めていきたいと思います。
学習指導要領には、「データの分析」について、こちらのスライドの冒頭のように書かれています。文章にすると2行ですが、実際これはけっこう大変なことではないかと、個人的には思います。
ただ、データ処理の作業に関しては、極論をすれば現在は「誰でもできてしまう時代」に入っていると思います。これは、ハード面で計算機の性能が向上して、非常に大規模なデータでも取り扱うことができてしまうという状況もありますが、一方で、ソフト面でもデータ解析用ソフトウエアが有償・無償を問わずたくさん出されています。ですから、データさえあれば、それを導入して、何も考えずにボタンをポチっとすれば、何か表が出て来る、グラフができるといった形で結果が出せてしまう時代になってきているのですね。
ここが10年、15年前とは飛躍的に違うところだと思います。もちろん、当時もSPSSやSASなどもありましたが、今のようにすごいことまではできませんでした。そういったところで、今や「データがあれば何でもできてしまう時代」になっていると思います。

経営システム工学科の1年生にはプログラミングの授業があります。私はそこでC言語を教えているのですが、レポートの感想で、「なぜPythonをやらないんですか。データ分析ならPythonでしょう。Pythonだったら書けるんですけど」という感想が結構あります。
ですので、高校生であっても、データ分析に興味があって、Pythonが書けて、ネット等でいろいろ情報検索ができる人であれば、先端のデータマイニングや機械学習の手法を実装することができます。様々なパッケージが用意されていますので、それを見つけて呼び出すことができれば、中身は理解していなくても、とにかくデータ解析ができてしまう時代になっているのです。

このように、データ処理自体が機械的にできるのであれば、「情報Ⅰ」でデータサイエンスを教えていく上でポイントとなるのは、その背後でどのような処理が行われているのかということや、データ処理をして出てきた結果から何が言えるのかを考え、身に付けるということであると思います。
これは、最初にご紹介したデータサイエンティスト協会の調査にもあったように、「どのように解決へ導いていけるのか」というところがポイントになってくるかと思います。
実際、この部分が理解できていないと、誤った分析結果を出してしまう可能性が大いにありますので、こういった部分をしっかり学ぶ必要があると思います。

データにだまされないために見極めなければならないこと
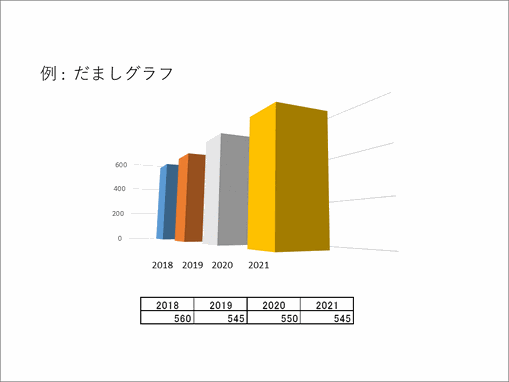
例えばこちらはよくある「だましグラフ」です。ぱっと見では単調増加に見えますが、実際は、スライドの下の表にあるように2018年が一番多いのです。
※クリックすると拡大します。
データをきちんと分析・処理されているか、こんな立体表示をするとどのように見えるか、といったことが見極められないと、うっかりだまされてしまうという例です。つまり、データの可視化でどのような操作がなされているか、情報デザイン的に学ぶ必要があるということです。
こちらはTOEICの学校種別の得点の平均点のグラフです。これを見ると、小学生の平均点が630点で最も高いので、「TOEICの成績は小学生がいちばん良い」という説明がなされる可能性があることになります。これは普通に考えてもおかしいですよね。

※クリックすると拡大します。
例えばこの母集団の人数は、小学生は231人です。この231人がどのような母集団から来ているのか、無作為抽出が行われているかどうか、ということがまず問題です。
つまり、小学校でTOEICを受検するのは、もともと相当英語がよくできる子どもでしょう。一方、大学生の受検者数が約30万人というのは、ほぼ無作為抽出に近いと言えます。
ですから、まずはこういったデータの出どころの特徴をきちんとつかむことが重要であると思います。こういったことはデータサイエンス、データ処理というより、データを取ってくるところの話なので、もう一段階前のことかもしれませんが、分析したデータが本当に正しいのかということに関しては、情報の出どころを見抜くということが、まずは大事であると思います。
おかしい結果が出てきたとき、どこを見たらよいのかを学ぶことが必要
もう少し高度な処理の例として、重回帰分析を行って何らかの予測をするという場面を考えてみましょう。例えばある店舗のオーナーが、売り上げの予測につながる条件を考えるとします。
店舗の売り上げには、来店客数や気温、天気が雨かどうか、といったことが関わってきそうだと考えて、そういったものが含まれるデータを持ってきたとしましょう。
重回帰分析をすれば結果が出ますから、予測式を出すことができます。そして、来店客数は何人くらい、気温が何度くらいと予測すれば、売上数が大体わかるので、翌月の在庫管理や仕入れ数の予測ができるということになるでしょう。
ところが、分析結果を適用したのに、なぜか売り上げが全然伸びないということがあります。
今回で言えば、雨の日と降水量には相関が強い関係にありますし、雨と気温にもけっこう相関があります。
このように、分析の条件とするものに相関があるもの同士を入れてしまうと、回帰の予測が不安定になりやすいという「多重共線性」と呼ばれる性質があります。
重回帰分析の理論をきちんと理解していれば、どういったものを指標に用いたらよいのかがわかってくるでしょう。もちろん、お店のオーナーさん自身がそこまで考えることは難しいかもしれませんが、データサイエンティストとしては、そういったところを考えていく必要性があるということになります。

もう一つ、「疑似相関」というものがあります。
よく言われる例に、「かき氷の売り上げと熱中症患者の増加」があります。
かき氷の売り上げと気温には正の相関があります。また、日中の気温と熱中症の間には正の相関があります。だから、気温が上がれば熱中症患者が多くなり、気温が上がれば売り上げも多くなるという状況なので、組み合わせを間違えると、「かき氷の売上増加が熱中症患者増加の原因である」という判断になってしまう可能性があるというものです。
相関があるもの同士を組み合わせたとき、こういった誤った結果が出て来たら、「何かおかしいぞ」と思うことが、最初のステップとして重要であると思います。つまり、そういったものを組み合わせてしまってはいけないのはなぜなのかを考えることから、疑似相関というものがあることを学んでいくのがよいと思います。ここをきちんと理解することで、先ほどの「かき氷と熱中症」のような誤った判断は起こらないようになるでしょう。
また、「ディープラーニングもいいことばかりではない」と書きましたが、これは、「ディープラーニングの手法の中身は、まだブラックボックスであることが多い」ということです。
ですから、「何かよくわからないけれど、何となくいい結果が出ている。だけど、どうしてそんな結果が出てきたのかはよくわからない」ということが結構あるのです。
何かおかしいとき、どこを改善したらよいのかがわからない状態で使うのは、やみくもに使っているのと同じです。そういった意味では、「中身」をよく知るということも重要になってきます。おかしい結果が出てきたら、ディープラーニングではなく、基本的な統計手法を使った方がよいかもしれない。あるいは、もっと初歩に立ち返ってグラフを見たり、集計データ自体を見て何かしらの傾向をつかんだり、といった分析をすることが重要になってくるかもしれない。そういった基礎を固めるのが、高校の「情報」の授業の役割ではないかと思います。

データの質と高校教科情報~使えないデータでは分析できない!
こういった形で、データの処理・分析ができてきた上で、次に考えていかなければならないのが「データの質」、つまり目的に合ったデータが集められているかどうか、という部分になります。
いわゆる機械学習のような、先端のディープラーニング的な手法で何かしらの状況を学習させようということであれば、やはりデータは多いに越したことはないですが、単に多くても仕方がないというお話です。

世の中では「ビッグデータ」という言葉はもうバズワード化していますが、世間に広まり始めた初期の頃は、「何でもいいから、片っ端から集めて、ニューラルネットに突っ込んだら、何か結果が出るんじゃないの?」ということをした企業も多いと聞いています。そして、そういった企業はことごとく失敗してると。
例えば、新商品を出したいときに、若者の趣味・嗜好を日頃の食料品や飲料品の購買履歴から分析するというお題があったとしましょう。
実際の購買履歴から分析するならば、性別、年齢(もちろん、若者なので年齢は必要ですが)、あとは品目の区別が必要です。
ただ、データとして取るときに品目を「飲み物」としても、コーヒーなのか、清涼飲料水なのか、お茶なのか、という区別がなければ、単に「飲み物をたくさん買っています」という結果になってしまって、これでは趣味・嗜好にはつながりません。このように、きちんとしたデータを集めて来なかったために、目的に合った分析ができないという事態が、実社会ではたくさん起きています。

次の例は、私が実際に経験した例です。「商用のトラックのGPSデータを解析して、運行の状況の確認や、敗者が効率的に運用されているか」という解析をしようとしたのですが、単に「トラックのデータ」というだけで、どのくらいの大きさのトラックなのか、4tトラックなのか10tなのかという情報がありません。
さらに、トラックには普通GPSデータの取得のために個別にIDが割り振られているはずなのですが、なぜか同じトラックが、今東京で走っていたのに、1秒後に鹿児島で走っているといったデータが散見されるという状態でした。そうなると、このままでは何の分析もできないので、まずデータそのものを見て、おかしいものを洗い出さないといけないね、ということになります。
また、「購買行動から消費者志向を抽出して推薦商品を決めたい」というケースがあったのですが、このときは購入者の大多数は1回しか購入しておらず、またデータが1年分しかないというものでした。そのため、次に何を買っているかという行動履歴がほとんど取れないため推薦が難しく、かつ1年分のデータでは季節性による傾向を見ることもできませんでした。
ですので、データはあっても、本来分析すべき購買行動に対するデータとしては不足していて、分析の難易度が格段に上がってしまう、もしくは、本来目的としていた推薦の精度が落ちてしまうということになってしまいました。

分析のポイントは「データの質」~まず基本的な統計処理をしてみよう
データの質を見るとき、基本的にこういったヒストグラムや、散布図を書いてみるだけでも、いきなり分析に入るのとでは全然違ってきます。
例えば、ヒストグラムを書くことで、平均値や中央値がどの辺りか、分散はどれぐらいなのか、というのがわかってきますし、散布図を書くと、「何か外れ的なデータがあるけど、これは外れ値として扱っていいのかな」といったところを意識することができます。
こういった可視化は、Excelなどを使ってもできますが、実際に処理に持ち込む前の段階でこれを行っておくこと自体が、データ処理、データ分析の第一歩になってくると思います。
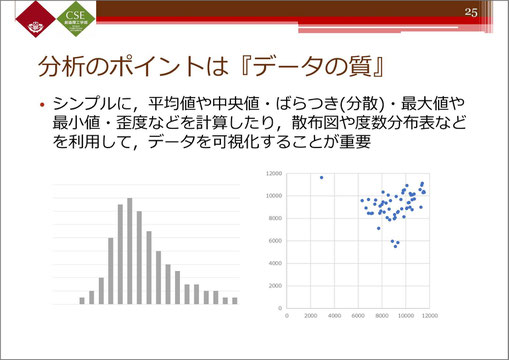
※クリックすると拡大します。
AIについてもう少し先端的なお話をします。
AIにデータを入れると、AIは入れられたデータに対して学習します。ですから、誤ったデータを学習すれば、当然AIは誤った判断をすることになります。
ですから、AIを正しく動かそうとするなら、まずは正確で精度の高いデータを入れなければダメということです。
例えば、将棋にはプロ棋士が長年積み重ねてきた指し手の手順(棋譜)があります。そういった棋譜をAIにどんどん食べさせていくと、非常に正確で質の高いデータになっていくので、人間をはるかに凌駕するような状況になっていきます。逆に、質の悪いデータを食べさせると、AIはその程度の学習しかせず、使い物にならない結果しか出さないということになります。
もう一つ、これが実社会では非常に重要なことですが、AIが出した答えというのは確かに良さそうなのですが、ではなぜこれが良いのか、ということについては説明不可能なことが多いのです。
この結果で本当によいのかという可否、あるいは善悪の判断をどうつけるかということは、今後情報科の教育で重要になってくると思います。

まずは身の回りの気になることからデータを取って触ってみよう
「情報I」の学習指導要領には、「データの分析」で身に付けるべきこととして、このスライドのようなことが書かれています。
「情報活用能力」として、質の高いデータを収集し、適切なデータ分析手法を使って正しく理解し、伝える能力を養うことが非常に重要になると思います。それが今後、大学、あるいは社会で出てから必要になってきます。

先ほどから申し上げているように、今お話ししたことはかなり高度な内容なので、これを実践しようとしても、かなり大変であると思います。
とは言っても、データを触らないとデータサイエンティストもただの人になってしまうので、まずは何でもいいのでデータを触ってみるところから始めましょう、というのが個人的な思いです。
基本的には、データ分析というのは試行錯誤の連続です。
一度で良い結果が出るということはまれなので、何度もデータ処理を行って、結果を見て、「何かおかしい。どこか直した方がいいのか」とか、「もともとの目的は正しかったのか」ということのチェックを行って、また分析をし直す、という形で常に手を動かしています。
そういった手法を高校生にもぜひ経験してほしい。そのためには、とにかくデータを扱ってみましょう、というところからスタートするのがよいと思います。

では何から始めればよいのかということになりますが、基本的には日常の至るところにある素朴な疑問から取り上げていけばよいと思います。そうすることで、たぶん高校生も食い付きが良くなってくるでしょう。日頃何気なく「なぜ」「どうして」と思うことが、データを扱ってみるきっかけになると思います。
例えば、ジャンケンに強い・弱いということは本当にあるのでしょうか。実際、勝ち負けに特徴があるとしたら、その特徴を出すには、何回くらいジャンケンするとわかってくるのかということになります。
ジャンケンというのは、意思決定では非常に重要なファクターです。「将来を決めるジャンケン」というものもありますので、ジャンケンの強い・弱いというのは、生徒たちにとっても、けっこう重要なことかもしれません。

「子どもの頃から牛乳を飲むと背が大きくなるというのは本当か」などというテーマはいかがでしょう。私は、牛乳をたくさん飲んでいたはずですが、なぜか背はあまり伸びませんでした。実際牛乳と身長に関係はないのかもしれませんし、私だけが例外的だったのかもしれません。その辺りを調べるために、実際にデータを取って本当に身長が伸びるのかどうか、ということをまとめてみるのもおもしろいかもしれません。
ただし、このデータを取るときには、スライドにあるように、身長にコンプレックスがある人もいるといったデリケートな部分もありますので、例えば実際の身長ではなく、小学校1年生から何cm伸びたかというデータを取るという配慮をするのがよいかと思います。

こういった身近なことから始めていくと、データを取ることはできます。取ったデータで集計表を作るだけで、すでにかなり特徴が見えてくると思います。
そこで、例えば先ほどの牛乳と身長の関係であれば、「牛乳を飲んでいた人の方が身長の伸びが大きい」となったとき、伸びが大きい人の中で、飲んでいた人数が100人、飲んでいなかった人が80人だったとしたら、本当にそれで差があると言えるのかなと考えていくと、次の段階の統計解析、いわゆる仮説検定につながります。その意味で、こういったデータを集計して表にするだけでも、かなりいろいろなことが見えてきます。
先ほどお話ししましたが、マーケティングに興味がある人は結構多いと思います。
高校生でも、webサイトで物を買ったことがある人は、実際なぜ自分にこの商品が推薦されるのか、自分が見ているwebサイトの横に、なぜこんなバナー広告が出てくるのだろうと考えると、自分の行動のデータが流用されているのではないかと思うことはあるでしょう。
こういったデータは、実際はなかなか収集することが難しいのですが、逆に言うとそれだけ価値があるのだ、ということも学んでもらえると、「データの質」という意味とはまた違って、社会における「データの(金銭的な)価値」といったものについて考えるきっかけにもなるかと思います。

マーケティングでデータが比較的取れそうなことの例です。コンビニやコーヒーショップが、隣同士とか、かなり近い位置関係にあることがよくありますね。同じ店種なのに、どうしてそんな近いところにあるのかという話になったとき、店舗の位置のデータを取ってみれば、本当に近い位置にあるのか、実際はそんな近くないとか、あるいは近そうに見えても間に大きな幹線道路が走っていて、実は遠いことになるといった、いろいろな見方が出てくると思います。
そういったところを踏まえて、実際に近い位置かどうかを検証するというのも、一つのアイデアであると思います。
これは、「ホテリングの立地モデル」という、いわゆるOR(オペレーションズリサーチ)の分野の有名な研究です。もともとは1929年、日本で言えば昭和4年の研究ですが、その当時すでにこういった数学モデルがあって、ある条件をそろえると、一番効率的な位置はお互い隣り合う同士の真ん中に建てるとよい、と言われています。そういった話とのつながりを見せるのもよいかと思います。

都市伝説をデータから証明、部活の必勝パターンを見つける…楽しく分析することがポイント
この他にも、都市伝説系や言い伝え系、ゲーム系などで言われていることについて、実際にデータを取って調べてみるというのもおもしろいと思います。
例えば、「1から9までの数字の中で好きな数字を一つだけ選んでください」と言ったときに、「7」が選ばれることが多いとよく言われるが、なぜか、ということがあります。本当に「7」が選ばれることが多いのかということを、きちんと解析することから始めるということもできますね。
そういった日常のちょっとした疑問から始めていくことで、非常に楽しくデータ解析ができるのではないかと思います。

スポーツはデータの宝庫です。例えば野球で言えば、「2点差で負けている7回裏・ノーアウト1塁の状況で、送りバントをするのがよいのか」といったものも、データ分析で勝ちパターンが見えてきます。
こういったスポーツ系のデータサイエンスは、今、非常に熱い領域で、高校でも取り入れているところがたくさん出てきています。
ピッチャーやキャッチャーの配球などは、彼らは無意識に頭の中でやっているかもしれませんが、まさしくデータサイエンスです。こういったところは、部活をやってる人たちにとっては非常に面白いテーマになるのかなと思います。
このように、きっかけは日常生活の中にあふれています。そこからデータサイエンスにつなげていけば、学習指導要領に書かれている内容も少しずつ実現していくのではないかと思っています。

データ分析は「まずやってみる」ことから始まる
ここまでお話しした内容をまとめるとこのようになります。
私の専門が経営システム工学科なのでPDCA(Plan、Do、Check、Action)と書きましたが、プランを立てて、実際にデータ収集から分析処理までやっみて(Do)、チェックして結果を分析して、次に何らかの対応を起こしていく(Action)というPDCAを回すのがデータ解析そのものになっていき、学習指導要領にあったデータサイエンスのそのものの習得になっていくのではないかと思っています。
このように、データ分析は「まずやってみる」というのが一番です。試行錯誤こそが、データサイエンスのまさに第一歩、一番重要な肝であると思います。いろいろな失敗をすることで学ぶこともあります。もちろん、結果がわかりやすいものもありますが、先生方でもなかなかわからないこともあるかもしれません。そういった時は、生徒たちと議論しながら面白い結果を導き出せたらよいと思っています。

データ分析を実際にやってみてわかることを、経験談でお話ししますと、まずは、「欲しいデータが集まらない」ということ。これは大学の研究でも同様です。
本当に重要なデータはお金になるので、企業は絶対に外に出しません。ですので、学生が、そういったデータを使って研究をしたいと言っても、それは難しいことであることを説明する必要なことがあります。そこでなぜ難しいのかを分析することも重要かと思います。
ただ、オープンデータだけでも解析できることは多いので、そこからやってみるというのもよいかもしれません。例えば、「雨が降ると、電車の遅延が起きやすいか」ということを調べようとするなら、気象データは気象庁やwebニュースなどから入手できます。遅延情報も、各鉄道会社で遅延情報を出しているので、これもわかります(もちろん、毎日調べる必要はありますが)。
また、webスクレイピングを使えば、twitterなどの公開情報から集めてくるということも可能です。そういったところから、遅延が起きている(いない)ことや、遅延の起きやすさも、分析できるかもしれません。
さらに「何分くらい遅延するか」ということまで調べようとすると、もう少し詳細なデータが必要になってくるので、オープンデータだけでは難しいかもしれません。その辺りの程度感については、分析しながら慣れていけると思います。

データの分布を見る目を養う
また、「データはあっても、どう分析していいかわからない」ということがあるかもしれません。そういうときは、まずデータを集計したり、図で可視化したりするだけでも、糸口がわかることがあります。
もう少し高度な話になると、データの分布を見るということが重要になってきます。

例えば、1日のスマートフォン利用時間の集計を取って、グラフを作成し、どのような分布に従っているかチェックしたときに、例えば下部の上側の図のような2つの山のある分布になっていたとします。
こう見ると、1つの正規分布には従っていませんが、よくデータを見てみると、下の図のように2つの山に分解できるかもしれません。これは経営のQC(品質管理)でいうと「層別」という話になってきます。
この2つのグループは、それぞれは正規分布に従ってると見てよいかもしれません。ここで、本当に正規分布に従っているかどうかを確認するためには、「正規性の検定」を行います。この辺りは、高校の「情報」とは少々分野が違いますので、状況を見ながらやっていただければと思います。
そして下の図のように、2つの正規分布があったとき、この2つの母集団の差を検定して、確かに差があるね、という解析方法もできます。
このように、分布がわかれば仮説検定の評価手法も明確になります。例えば、母集団が正規分布に従うことがわかれば、平均値の検定や分散の検定は、t検定であったり、f分布の検定だったり、χ2乗分布だったり、といった手法を使えばよいでしょう。
逆に、正規分布に従っていないとすれば、それを使わない検定方法を考えることにつながります。このように、データの状態に合わせた分析ができるようになるためにも、まずは手を動かすということが重要であると思っています。


データ分析は試行錯誤の連続。対話を通して発見を導く
ここからは、今日お話ししたことのまとめです。
まずはお固いまとめです。
ここ数年、社会においても大学においても、情報教育やデータサイエンスの役割が非常に重要になってきています。あらゆることが、データなしには語れない。討論番組でも、相手を論破するためには、根拠となるデータが絶対に必要だという時代です。
データサイエンスは、社会の多様な意思決定にダイレクトにつながります。今回の学習指導要領を踏まえた上で、実際にデータを使えて、かつ説明できる人材がどんどん育っていったらいいのかなと思っています。

一方こちらは柔らかいまとめです。何度も言いましたように、まずは疑問に思ったことが解決できそうなデータを集めて、それを触っていきましょう、ということです。簡単に集計するだけでも何かが見えてきますし、そこに統計手法を使えば、さらに面白いことがわかってくるかもしれません。
データはあくまでも材料です。材料の使い方はいくつもありますので、切り方や調理方法で全く違うものになってくるでしょう。それと同様に、いろいろな切り口から多様な見方ができると思います。
最後になりますが、データサイエンスをやっていると、多分、先生でもわからないことが出てきます。私たち大学の研究者でもそれは同じで、どうしてこんなに変なことになるのか、ということはしばしばあります。
そういうときは、データを通して生徒たちと対話しながら分析を進めていくことが重要だと思います。そうすると、生徒からの楽しい発見がたくさん出てきます。「僕もわからないので、一緒にいろいろ試してみよう」ということからいろいろな学びを得ていくのが、データサイエンスでは重要なのかな、と思っています。

※一部、先生のご講演時から差し替えたスライドがあります。ご了承ください。
東京都高等学校情報教育研究会 基調講演より