










高校生のためのコンピュータサイエンスオンラインセッション2020
データサイエンス x 介護・医療
九州工業大学 大学院生命体工学研究科 井上創造先生
ゲームをするために毎回一からプログラムを書いた少年時代

今日は、データサイエンスと介護と医療というテーマで話をします。最初に私の簡単な自己紹介をいたします。
私は中学校までファミコンを買ってもらえなかったという家庭に育ちました。ゲームをしたくてたまらなかったのですが、なぜか家にはパソコンがありました。
親は「パソコンでゲームができる」と言うのですが、どうやったらできるかわからない。そこでいろいろ調べたり本を買ってきたりして、ゲームをするためにはプログラムを入力しなければいけないことを知りました。
そして、ゲームで遊ぶために、毎回電源を入れて、ゲームのプログラムを入力して、遊び終わったら電源を消して、ということを繰り返しました。その頃は、ハードディスクなんてものはなかったので、遊びたいときは毎回電源を入れて、プログラムを毎回最初から入力しなければなりませんでした。そんな少年時代を過ごして、高校・大学は吹奏楽やバンドなど音楽にはまって、今に至ります。
大学でもコンピュータを学びました。当時、学部の授業に「CPU設計」という演習があって、これが一番大変でしたが、今でも思い出に残っています。コンピュータの中身を全て一から作るというのはエキサイティングですし、後になって自分でやろうと思ってもできるものではないので、これは大学に行ったからこそできたことだと思っています。
こちらが私の研究室の紹介です。現在は、「行動を認識するIoT」「医療・介護にビッグデータを応用する」というキーワードで研究を行っていますが、この内容については後でお話しします。研究室のメンバーの男女比は同じくらいで、女性のほうがちょっと多いですね。また、半分くらいが留学生で、世界中から本当に優秀な人がやってきて切磋琢磨しています。

※クリックすると拡大します。
また、最近は合同会社AUTO CAREを設立して、ITを介護や医療に応用しています。今日は、データサイエンスがこういった分野にどのように活かされているか、というお話をします。その中で、昨日までのオンラインセッションを見ていると、高校生の皆さんから進路の選択に関する質問もけっこう来ていたので、情報科学にまつわる人生観についてのお話もしたいと思います。

データサイエンティストは「最も魅力的な職業」
まず、データサイエンスって何だ、というところからお話ししましょう。「データサイエンティスト」が注目を集めていますが、これは2012年にGoogleのチーフエコノミストの方が「これから10年で最も魅力的な職業だ」と言ったことから、俄然注目をされています。
では、データサイエンス、データサイエンティストとは何か。データサイエンス協会の定義には、「データサイエンス力、データエンジニア力をベースから価値を創出して、そこからビジネス課題に答えを出すプロフェッショナルである」と、カッコイイことが書いてあります。

もう少し具体的に説明します。定義Aの「データサイエンス」というのは、もともとは統計学です。皆さんも数学で平均や分散といったことを習ってきたと思いますが、そういった統計学から発展してきました。データサイエンスでは、これにコンピュータを使います。スライドの定義Bの「データエンジニアリング」はコンピュータのことを指しています。定義Cの「ビジネス」は、要は「役に立つ」ということです。つまり、「統計」と「コンピュータ」と「役に立つ」の三つが揃ったものがデータサイエンスだということです。最近は、さらにトレンドになっているAIや機械学習の技術を積極的に使っています。
科学研究の新たなパラダイムとして
今の説明はビジネスの話からでしたが、別の説明として、なぜ今データサイエンスが注目されているのか、というお話をします。
2009年に、情報系のノーベル賞といわれるチューリング賞を受賞したジム・グレイさんが、科学研究手法の新しいパラダイムを提唱しました。これは、現在の学問につながる研究や科学がどのように進んできたかということを、わかりやすく説明したものです。

最初にあるのが「実験」です。実験というのは、例えばガリレオが、ピサの斜塔から軽い球と重い球を同時に落として落ちる速さを測ったというようなものですね。
第2が「理論」です。理論というのは証明です。例えばニュートンは、今と同じように感染症の蔓延で大学に行けなくなって、その間に万有引力の法則を思い付いたと言われますが、そのような理論です。科学は、ほんの数十年前までは、この実験と理論の二つで進んで来ました。
そこにこの数十年で、「コンピュータシミュレーション』が入ってきました。例えば、津波の被害がどこまで及ぶかをコンピュータで計算して予測する、というのがこれにあたります。
そして最近言われているのが、世の中にたくさんあるデータを使って、これまでのような理論やコンピュータシミュレーションを活用して、新しい科学の方法論を作っていく、「第4のパラダイム」というものです。実は科学の分野でもデータサイエンスが非常に注目されています。
ですから、大学でコンピュータサイエンスの領域に進まなくても、例えば理論物理や、実験物理を学んだ方が、キャリアチェンジをしてデータサイエンティストになる、ということがけっこう多いようです。
理系大学生が必ず習うこと~データから式を作る
そのようなデータサイエンスの中でも、機械学習の考え方が一番面白いと思いますので、詳しくご紹介したいと思います。
このスライドにあるようなグラフ、例えばy=2x+1のグラフは、中学生・高校生の皆さんは簡単にわかると思います。高校までは、こういう式が出てきたら、「値は何か」とか、「グラフを描いてみましょう」「式を変形しましょう」といったことを考えますね。

ところが大学、特にほとんどの理系の大学ではそうではありません。実験をすると、スライドの赤い点で示すようなデータが取れます。実験データは1回ごとの試行で取れるので、このようにそれぞれプロットするわけですね。

これに線を引いて式で表わそうとするののですが、どうしても誤差があるので、この赤い点を全て通るような線はなかなか引けません。では、どのように線を引いたらよいか、ということが問題になります。
つまり、高校までは与えられた式がすでにあって、そこから何かをするのですが、大学ではデータがあって、そこから式を作ることを考えます。これが、実験を伴うあらゆる研究で必要になります。心理学や経済学など、文系と言われる学問でも同様です。

この実験データをどうやってグラフにするかという方法のコンセプトの部分を説明します。この赤い点が「実験値」、青い線は、まだ確定していませんが「理論値」とします。実験値と理論値の差が「誤差」というわけですね。
そして、この誤差をなるべく小さくできるような直線を引きたい、ということです。
高校までは、y=ax+bのaとbはわかっていて、xとyがわからなかったのですが、今度はxとyはたくさんわかっていても、aとbがわからない、という逆転が起きるわけです。

今度はこの誤差を小さくする方法です。
一つひとつの誤差は、(yi-(axi+b))という式で表されます。iとは、i番目のサンプルという意味です。あるデータxiがあったとき、この高さがyiです。このyi と理論値の差が誤差になるので、この合計を最も小さくすればよいわけです。
誤差がプラスとマイナスで出てくると、足し合わせた時に打ち消し合ってしまうので、絶対値を2乗してその和を小さくすることを考えます。

昨日のGoogleの飯塚さんのお話で、最適化の関数f(x)を最大化する、ということがありました。最大と最小という違いはありますが、実は一緒のことで、f(x)を最小化するための最適化問題ということになります。これは、実は最近のディープラーニングやニューラルネットワークといった機械学習で使っている考え方と全く同じです。
もう一つ、この一番下の式にargとありますが、これはこの右側の式を最小化する、という意味で、プロが使う表現です。このように、データがあっても、パラメータのaとbがわかっていない、という問題を解くのが機械学習で、データサイエンスでも非常によく使います。

xとかyとか言われると、数学が苦手な人には面白くないかもしれませんが、コンピュータサイエンスをやってると、これが本当にありとあらゆるものに使えるのです。例えばメールの本文がxで、これが迷惑メールかどうかというのがyで、といった面白いことも、関数からわかってきています。
様々なデータをコンピュータの中でどのように表すか
では、どのようなデータがそのようなxやyになるのか、コンピュータサイエンスの基礎的な内容を紹介していきます。
まず数字は、コンピュータの中ではビットで表されます。ビットというのは、0と1で表す2進数のことですが、コンピュータの中に実際に0や1という数字が入っているわけではありません。例えば、ハードディスクの中だったら磁石であったり、導線の中では、そこにかかる電圧だったりといった、様々な物理的な表現で表される情報を、ビットとして2進数で表しています。
小数は、また別の方法で表します。スライドの右側のように、例えば5.0×10-5であれば、5という数字と、-5乗の5、さらにプラスかマイナスか、何乗か、という形で表しています。

※クリックすると拡大します。
他にも表やベクトルや行列も表すことができます。これは多変量データといって、データサイエンスではこの形式を標準的な形として使っています。

一方、例えば「あ」という文字をどのように2進数で表すかというコードは、文字コードというルールであらかじめ決まっています。ただ、データサイエンスのために自然言語処理という文章の処理をする際には、文書単語ベクトルというものを作ります。これはベクトルを実際に作るわけではなく、概念的なものです。
例えばですが、私の日記の文中の「九州」という言葉の出現を調べる場合は、左右の軸の方向に5万語の「辞書」があるとすると5万次元のベクトルがあり、縦方向には文書に世の中の文書の数だけのベクトルがあって、この中で私の文章に九州という単語が出てきたら1、それ以外は0という表現をしていきます。これを文書単語ベクトルといいます。ただ、実際これはあまりにも大きすぎて、先ほどの私の日記に出て来る単語という程度ではほとんど0になってしまって、表現することができません。こういったものをスパース(スカスカな状態)といって、少ない情報から全体像を的確にあぶり出す科学的モデリングのやり方が研究されています。

次に、音です。今、NHKの朝ドラで蓄音機の話が出ていますが、蓄音機というのはアナログで、実際にレコード盤に針で掘った溝をなぞる時の音、つまり振動をアサガオのようなスピーカーで増幅して聞くわけです。
振動の大きさは、溝の深さと比例します。
一方、今のデジタルの音源は、音をいったん0か1かの数字に変換しています。

画像も数字に変換します。画像は、拡大して見ると、ピクセルとかビットマップという小さな色の点の集まりになっていますが、その一つひとつをRGB、つまり赤(Red)、緑(Green)、青(Blue)の小さな点に分割して、それぞれの値を数字で表しています。

ここまで非常に簡単な説明をしてきましたが、実際にはこれらを圧縮したり、効率よく使ったりするために、コンピュータサイエンスの様々な研究の成果があるわけです。そういった努力のおかげで、あらゆる世の中のデータ、情報が、0と1で表されるようになっています。それらを、先ほどの機械学習を使っていろいろ分析することができるというのが、データサイエンスの非常に面白いところだと思います。
機械学習は何に役立つのか?
では、データサイエンスの中で機械学習はどのように役に立つのか、ということについて、三つの代表的な応用例を紹介したいと思います。
一つ目は「推定」です。先ほどからお話ししているように、入力したxから出力f(x)を得る。例えば音声を入力したらテキストが出力される音声認識、画像を入れたら単語が出てくる画像認識、テキストを入れたら話題が出てくる自然言語処理といった、様々な認識技術と呼ばれる技術があります。
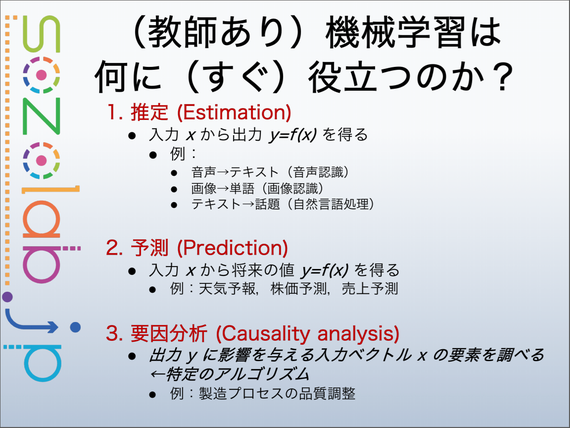
その技術を少し改良すると、将来の値を得ることができるようになります。予測ですね。例えば天気予報、株価予測、売り上げ予測みたいなこともできます。
さらにもう少し進むと、要因分析といって、任意のy=f(x)に対して、どの時に xが役に立ったのか、効いたのか(=原因、要因の候補)ということを調べることができます。
機械学習の特性を介護・看護・医療の現場に役立てる
私が行っている介護技術の研究では、この「推定」の働きを応用する研究を行っています。右下の患者さん役の人は、スマホを胸ポケットに入れています。スマホの中には加速度センサーが入っていて、この人が今何をしているか、ということを認識して、行動との記録ができます。これが行動認識技術です。

この技術を、介護施設の現場で4か月実証しました。その施設では、もともと入所者の方の介護記録を書いていました。その記録作成に1日当たり約1時間取られていましたが、スマホにこのアプリを入れることで効率化することができました。最初は、なかなか慣れなかったですが、行動の記録がどんどん蓄積されていくと、介護記録自体をどんどん自動化していくことができました。全自動は難しいのですが、それでも日本全国で今、介護や看護の人材不足の問題は深刻になってきていますので、介護記録にかける時間を削減して、なるたけ介護そのものに時間を使ってもらえるようにできたらと思います。

次に予測の例です。今度は病院の看護師さんで実験をしました。病院で看護師さんにビーコン(一定の時間間隔に無線で半径数メートルから数十メートルの範囲に信号を発する装置)を装着してもらって、看護師さんが病院内のどこにいるかということを把握します。

※クリックすると拡大します。
例えば、入院病棟のどこにいるかがわかれば、どのベッドの近くでケアをしてるかということがわかります。どこのベッドかがわかれば、医療データから、そのベッドに誰がいつからいつまで入院していたかもわかりますので、そのデータと看護師さんの行動を統合して、スライドの真ん中のような表のデータにします。それを蓄積していくことで、例えば、明日はこの患者さんに対してこれだけ忙しくなりますよ、ということが予報として出せれば、これは看護師さんにとってありがたいことですね。
もう一つは、患者さんの健康状態の予測です。患者さんは、入院して1週間くらいで退院しますが、最初の2日目くらいまでのデータで、この患者さんは入院がちょっと長期化するのではないか、あるいは、退院されるときに本当に健康になるのか、といったことを予測します。

三つ目が要因分析です。先ほど患者さんの将来予測をしたのと同じ病院で、看護師さんがどのような看護行動をしたかという記録を使って、どの行動の・どのくらいの時間が、結果に効いたのか(あるいは効かなかったのか)ということを調べました。

ここでは、結果に効果がなかった看護行動に着目しました。そうすると、ここに書いているように、おむつ交換の時間の長さや、配膳・下膳(食事を出したり下げたりする)をどれだけ丁寧にやったかというところは、当然と言えば当然ですが、退院までの時間や、状態が早く良くなったということには、ほとんど関係ないということがわかってきました。
この結果を看護師さんとディスカッションして、これらの仕事は看護行為ではないので、他のスタッフと協力してやろう、という業務改善につながりました。

※クリックすると拡大します。
いろいろな例を紹介しましたが、データサイエンス、機械学習が面白いのは、本当にいろいろな分野のデータを扱うことができることです。その一方で、問題の構造は結構シンプルで、極端に言えば、xを入れたらyが出てくるようなfを作りたいということだけです。
ただ機械学習にはいろいろな分野があって、今お話ししたのは「教師あり学習」というのが中心でしたが、この他にも、画像を生成するとか、教師なしで学習するとか、ロボットなどに使われているような、使いながら学習するような強化学習といったいろいろなものがあります。こういったことをコンピュータと組み合わせると、データを集めたり、それを使って先ほど紹介したようなフィードバックをしたりと、とにかくいろいろなことができるというところが面白いところです。

一方、面白くないところがあるとすれば、私たち研究者はいろいろアイデアを考えるのですが、結構「それってGoogleがやってるじゃない」と言われることですね(Googleさんの前で(笑))。
データがないと何もできない⇔データがあれば誰でもできる?!
確かに、機械学習はデータがないと実は何もできないと言われています(実はこの言葉は私が考えたのですが)。データがないと何もできないけれど、データがあるところでは、基本いろいろなことができます。インターネット上にあるデータを使ってやれるということは、他の人もやれるということなので、研究者としてはどこに貢献すべきかということを考えなければならないと思います。
ですから、私の場合は病院や介護施設、そして在宅の患者さんのデータを使えるようにしていきたいと考えています。今は、病院には標準化された様々なデータがあって、これは皆さんの医療保険にも使われてます。
介護施設はまだまだデータが少なく、文章で手書きされていたりするので、いわゆる構造化されていないデータが多いので、なかなか分析しにくいですが、とりあえずデータはあるにはあります。これが在宅になると、データが何もないという状況ですので、チャレンジではありますが、そこで私は、データをうまく集めることを研究してやろうと思っています。

ところで、最近私はインターネットが使える介護施設はどのくらいあるのか、ということを調べてみました。これは検索しただけですが、入居者がインターネットが使える介護施設は4.7%です。一般の世帯は80%を超えているのに対して、極めて低い数字です。
今、私たちはこのオンラインセッションのように、遠隔の会議が簡単にできますが、介護施設には、こんなことが全くできない、当然ご家族とも面談とかできない、という方々がまだいらっしゃいます。そのために、運動不足になり、フレイル(加齢によって体力が落ちていくこと)になることで、閉じこもりがちになって認知機能が低下するということが、データとして出てきており、何とかしないといけないと思っています。なので、ぜひGoogleさんとも共同で何とかしたい、何とかしましょうと思っています。

情報科学は今いちばんエキサイティングな学問!
最後に、ちょっと人生観的なことをお話しします。1965年に、CPUのプロセッサメーカーのインテルの創業者のG.ムーアが「コンピュータの性能は1.5年で2倍になる」と述べ、「ムーアの法則」として知られていますが、実際にそうなりました。

この1971年というのが、インテルのチップが最初に出てきた頃ですが、2015年までに、性能は3500倍以上、電力効率は9万倍以上、コスト単価は6万分の1になりました。そして、2015年にインテルの当時の副社長の阿部剛士さんが言ったことですが、もしも自動車が同じ割合で進化してたら、車は時速48万キロで、燃費は1リットル当たり85万キロ走って、価格は1台4円になってないといけない、ということになります。こんな業界、他にありますか、ということです。情報科学というのは、これだけ進化する世界で、ここがエキサイティングなところだと思います。皆さんにも、使う立場もいいですが、できればつくる側にもなりたくないですか、ということが私のメッセージです。
「つくる」というのはCreativeということで、私は名前がそのまま「創造」なのですが、どうしたらCreativeになれるか、ということについて、私の思うところをお話しします。
大学に入ると、最初のうちは授業が多いと思います。そして、私の大学では、4年生から研究室に入りますが、そこで生活ががらっと変わります。そこでどういう態度や考え方をするかということが、実は、その後の人生に非常に影響があると思っています。

時間割は、研究室に入るまではぎっちりあったのが、研究室では空っぽになります。何もないときは帰るしかなかったのが、研究室にいるようになります。課題は与えられるものだったのが、自分で決めないといけなくなります。そして、態度としても「勉強します」ではダメで、「何かやってみた結果、こういうことがわかりました」ということで皆に貢献し、シェアするようなことが大事になります。締め切りも、だんだん守りにくくなってきます。そこのテクニックもいろいろ必要です。
もう一つ大事なのは、大学に入ると、GPAという成績が大事になりますが、研究室に入ると、今度はどんなに小さな世界でもいいから、そこで世界一かどうかというところが問われるようになります。その分野で、何が・どのように貢献できるかということを考えるのは、すごく面白いと思います。
前のセッションで、「大学や専門学校に行く意味はありますか」という質問がありましたが、私が聞かれたらこのように答えてます。
日本の年収の中央値というのは、350万円くらいだそうです。会社からすると、雇用するときはその倍くらいのお金を用意しなければならないのですが、その価値700万円を時給に換算すると、時給4375円です。つまり、仕事をせずに大学や専門学校に行くということは、1時間4375円を捨てるということになります。さらに学費も払わなければならない。
なので、それだけの学びをしたいなら行くべきであり、むしろ行くのであれば、それくらいの学びをしましょう、ということを、メッセージとしてお伝えしたいと思います。大学ではもちろん、これだけの学びはできますが、皆さん自身がその気持ちを持っていると、すごく楽しい学びになるかなあと思います。

ここまで、データサイエンスと介護医療のこと、そして私の人生観について、私の主観も交えてお話ししました。大学はすごく楽しいので、皆さんにぜひ学生でいられる時間をエンジョイしてもらったらよいと思います。
最近、私が学生に言ってるのは、責任は持てませんが、学生のうちに会社を作って、うまくいかなかったら卒業前にたたんで就職する、というのもありかな、ということです。コンピュータサイエンスを思い切り学んで、学生時代からどんどんチャレンジしてみてくたさい。

※井上先生は、ご研究の成果を介護業界に広めるために大学発ベンチャー「合同会社AUTOCARE」を
立ち上げ、スマートフォンAI行動認識とAIビッグデータ分析を生かしたサービスを展開していらっ
しゃいます。